
Your AI Agent Needs a Lifecycle, Not Just a Launch Date
Why treating agents as living systems—with specification, testing, staged rollout, and retirement—separates production from pilot projects.
Your finance team launches an agent to help with month-end closing. The demo is flawless. It pulls data from ERP, reconciles spreadsheets, and prepares adjusting entries. Three weeks later, a staffer notices the agent is using outdated accounting rules. The knowledge source was never updated. Nobody knows when the drift started. The agent keeps running, looking active, but quietly producing outputs that no longer comply with policy.
This isn't a hypothetical. It's a pattern playing out across enterprises right now. High enthusiasm during pilot. Slack attention once the agent goes live. And then the slow, invisible erosion of trust.
The root cause is a category error. We're treating agents like applications—deploy and forget—when they're actually something far more dynamic. An agent is a bundle of system instructions, a language model, tools, APIs, memory, approval policies, data sources, workflow orchestration, and human oversight. Change one component—swap the base model, add a tool, expand the knowledge corpus—and the agent's behavior can shift dramatically, even if the user interface looks identical.
The question isn't whether your agent works today. It's whether you can manage it from birth to retirement, not just from demo to deployment.
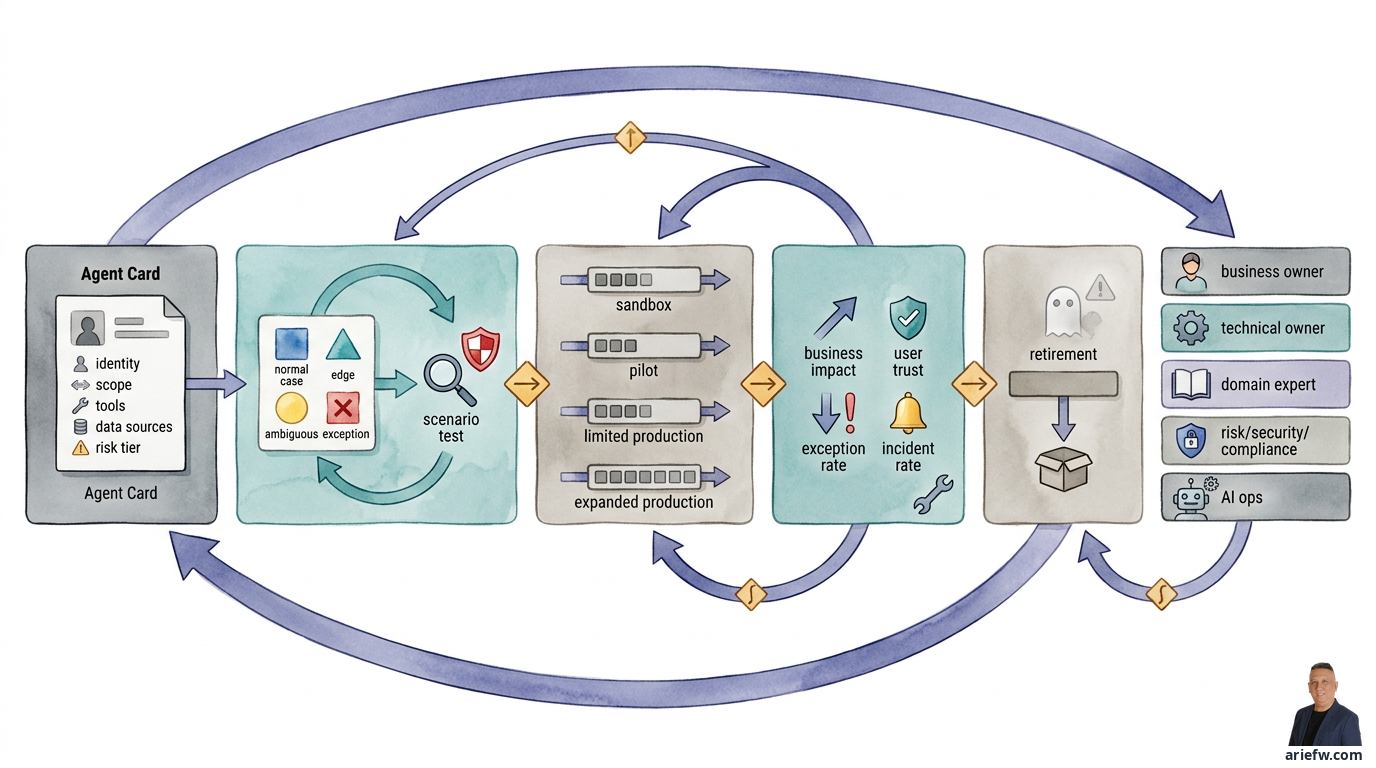
An enterprise agent needs a lifecycle, not just a launch date.
Start with an Agent Card, Not a Prompt
Most teams start building agents by asking, "What cool thing can we make?" The healthier starting point is, "What exactly is this agent supposed to be?"
Enter the agent card: a concise, formal document that defines an agent's identity and operational boundaries. Think of it as a birth certificate for your digital worker. At minimum, it should specify:
Business purpose and scope
Allowed inputs, outputs, and tools
Data and context sources
Business and technical owners
Risk tier and autonomy level
The agent card forces a shift in mindset. You stop seeing the agent as an "AI feature" and start seeing it as an operational unit. It also forces you to define success concretely. For an accounts payable exception handler, success might mean faster classification and fewer reworks. For customer operations, it might mean higher resolution rates without reopening complaints. For IT triage, it might mean more complete incident enrichment and consistent routing.
Crucially, a good specification also anticipates failure. Common failure modes include: misunderstanding intent, pulling outdated context, choosing the wrong tool, violating policy thresholds, escalating too often, or being overconfident on ambiguous cases. Document these upfront—they'll shape your testing strategy, guardrails, and monitoring.
And here's the non-negotiable: domain experts must be in the room from day one. Agents that touch enterprise workflows can't be designed by AI teams alone. You need people who know the business rules, the frequent exceptions, the tacit judgment calls, and the points where human intervention actually adds value. Without them, your agent will look smart in demo and fail in production.
Test Behavior, Not Just Output
Testing an agent isn't like testing a mobile app. And it's not enough to test whether the language model gives good answers. You need to test behavior in real workflow context.
Start with a golden dataset: a curated set of cases covering normal, edge, ambiguous, and exception scenarios. But that's just the baseline. You also need scenario tests that simulate end-to-end flows: input arrives, context is retrieved, tools are called, policies are checked, approvals happen, and an outcome is produced. For a customer service agent, does it process small refunds correctly, halt on large ones, and escalate when the customer history shows abuse patterns?
Because agents can act, testing must verify they only use authorized tools, pass correct parameters, don't bypass approval gates, and respect delegated authority limits. An agent that passes language quality tests might still fail operational control tests.
For production-bound agents, red teaming isn't a luxury—it's a requirement. The goal isn't cosmetic bug hunting. It's simulating attacks and conditions that could break controls: prompt injection, data leakage, privilege escalation, conflicting instructions. Can a vendor attachment trick your procurement agent into changing approval routes? Can a manipulated event trigger your IT agent into running a destructive runbook? Can someone extract another employee's personal data from your HR agent?
One principle often ignored: agents are not systems you test once and consider stable. Every significant change—model, prompt, tool, memory, policy, or context corpus—should trigger retesting. Otherwise, you get silent drift: the agent looks the same, but its behavior has changed, and you won't notice until there's an incident or a drop in trust.
Roll Out Like You Mean It
Never launch an agent to the entire organization at once. The safer path is staged rollout with four phases:
Sandbox: Controlled environment to validate specs and identify failure modes.
Pilot: Limited user group or case subset to test real-world behavior and human handoffs.
Limited production: Live operations with narrow scope, low transaction thresholds, or constrained autonomy.
Expanded production: Full scale, but only after quality, control, and value are proven.
This matters because agentic AI touches your operating model. If you roll out too fast, you don't have time to adjust SOPs, approval queues, support models, and human roles.
Once live, monitor four signal groups:
Business impact: Is cycle time improving? Backlog dropping? Touchless rate rising?
User trust: Are people accepting agent recommendations, or is override rate high?
Exception rate: Is the agent escalating too often? That might mean specs are too narrow or quality is insufficient.
Incident rate: Any policy breaches, tool misuse, data exposure, or actions requiring rollback?
Monitoring should feed into continuous improvement, not just a passive dashboard. Post-deployment is where the real work begins: tuning prompts, updating policies, improving retrieval, adjusting thresholds, and sometimes raising or lowering autonomy. Every agent needs a review cadence—who reviews, how often, what metrics, and when changes can be released. Without this rhythm, agents degrade slowly while looking "active."
The Hardest Decision: When to Retire an Agent
One mark of mature governance is the ability to sunset agents that no longer deliver value. Many organizations are great at launching pilots but terrible at retiring capabilities that have become expensive, redundant, risky, or irrelevant.
Clear signals include: stagnant or declining business value, operating costs exceeding benefits, persistently high exception rates despite tuning, regulatory changes that invalidate the design, source systems that have evolved, or the agent becoming duplicative as similar capabilities are embedded in enterprise platforms.
Retirement isn't just turning something off. It means deactivating the runtime, revoking access and credentials, removing or archiving the agent from the registry, stopping monitoring and billing, and documenting the reasons. Otherwise, you accumulate zombie agents: still holding access, still listed in systems, but with no clear owner. That's not just waste. It's a security and governance risk.
What This Means for Builders
If you're building agents today, here's what you should take away:
Agents are not static artifacts. They're dynamic systems that require ongoing management, not just deployment.
Specification is the hardest part. Getting domain experts to define scope, failure modes, and success criteria upfront saves months of rework.
Testing must cover behavior, not just output. Your golden dataset is necessary but not sufficient. End-to-end scenario tests and red teaming are table stakes.
Staged rollout is non-negotiable. You can't learn everything in a sandbox. You need real users, real data, and real consequences before going full scale.
Retirement is a feature, not a failure. Zombie agents are a liability. Build the off-ramp before you build the on-ramp.
Implementation Lens
Here's how to operationalize this in your team:
Create an agent card template and make it a prerequisite for any agent that touches production data. Store it in your documentation system alongside the agent's code and configuration.
Define material changes that trigger retesting: model swap, prompt rewrite, tool addition, policy update, context source change. Document the retesting criteria for each.
Build a rollout gate checklist with sign-offs from business owner, technical owner, domain expert, and security. No gate, no promotion.
Set a review cadence for every production agent. Monthly for high-risk agents, quarterly for medium-risk, semi-annually for low-risk. The review should include metrics, incident logs, and a decision to continue, modify, or retire.
Establish a retirement process that includes credential revocation, registry removal, monitoring stop, and documentation archive. Make it as easy to retire an agent as it is to launch one.
The Operating Model That Makes It Work
Lifecycle management requires clear roles:
Business owner: Responsible for business outcomes and relevance.
Technical/product owner: Responsible for design, release, and operations.
Domain expert: Maintains rule accuracy and exception handling.
Risk, security, compliance: Assess controls, policy, and material changes.
AI ops/platform team: Manages observability, deployment, evaluation, and incident response.
This is why agent lifecycle management can't live entirely inside an experimentation project. It needs a cross-functional operating model.
What to Do Now
Lifecycle management is what separates organizations that demo agents from organizations that operate digital labor responsibly. Without this discipline, scale only amplifies risk. With it, agents can evolve from experiments into safe, measurable, trustworthy enterprise capabilities.
A few decisions to make today:
Will every production agent have a formal agent card?
What changes are considered material and require retesting?
Will all agents pass through staged rollout gates?
What's the post-deployment review cadence?
Is there a formal retirement process?
If your agents are still built from prompts without specifications, if ownership is unclear, if testing only covers clean demo cases, if changes go straight to production, if post-launch metrics are limited to latency and uptime, if unused agents still have system access, or if there's no way to formally retire a failing agent—then you're not ready to scale.
The reflective question for leaders: Are your agents being treated as operational assets with a formal lifecycle, or as experimental applications? Do you know which agents are actually improving process economics, and which are just adding complexity? If you launched 20 agents in the next 12 months, would you have the mechanisms to test, monitor, improve, and retire all of them with discipline?
For a deeper dive into the agent lifecycle arc—from agent card specification through testing, staged rollout, monitoring, and retirement—with feedback loops and an operating model swimlane ensuring governance at every stage, read the full article.